Going across and beyond
I realized that one of my favorite work-related stories from last year is worth sharing on this blog, because there is such a powerful lesson in there. It’s a great example of how useful it can be if you take a step back and look at the larger picture. I’m quite sure that you’re going to enjoy it.
Getting rate limited
As I was going through my work emails, trying to stay on top of all the things happening within in my department, I came across a technical document that caught my attention.
From that document I learned that my colleagues were looking for a way to reduce the amount of traffic we triggered on one of the services our own systems depended on. That service had started to rate limit our systems, which had lead to a surge in errors on our side. My colleagues had already identified the source of the errors: a change in one of the products that consume our systems. They were now looking for a way to resolve the issue.
Wow. That was probably too much to take in at once, so let me slow down a little and explain things properly first, giving you a bit of additional context along the way.
A bit of context
I am one of several thousand employees working for a company that develops, sells and operates a range of SaaS products. And although these products are quite different from each other, they still share functionality.
Some of that shared functionality had been taken out of the products and had then been consolidated into so-called platform services. There is, for example, only a single identity and account platform that all of the products depend on.
It’s fairly common for a platform service to have dependencies on other platform services too, thereby creating a tree-like structure.
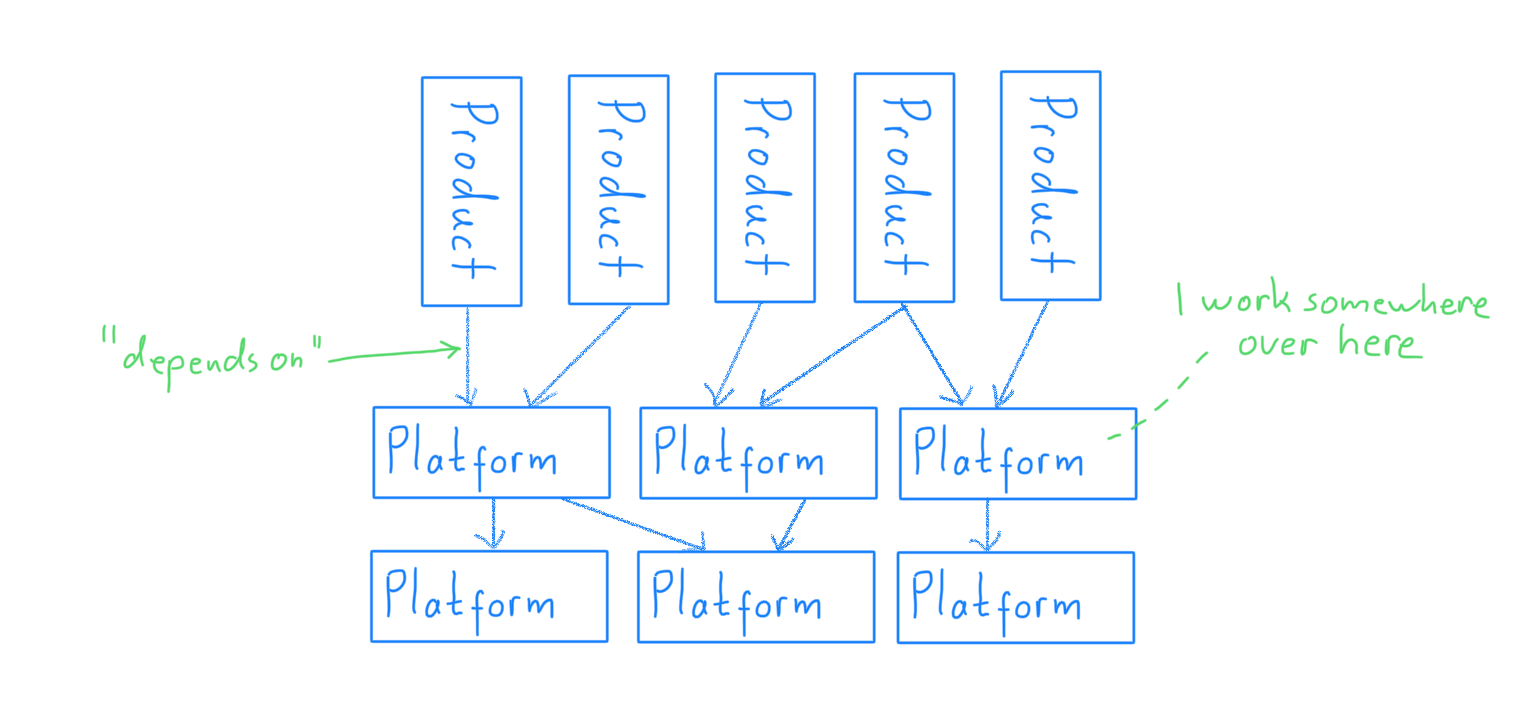
Products and platform services are generally associated with different departments. Teams and reporting lines change frequently within a department, but changes between departments are rare. In accordance with Conway’s law, each department builds their software independently of others.
Most importantly, in order to serve the company’s customers, the software from various departments must work together to produce the desired results. If an error occurs in any of the systems, it will propagate through the chain and eventually turn into a problem for the customers.
As I mentioned earlier, a change in one of the products had led to an increase in traffic for one of the platform services owned by our department. Although our systems could handle that traffic well enough, one of the services we depend on could not and therefore started to rate limit us. The rate limit errors flowed all the way back to our customers.
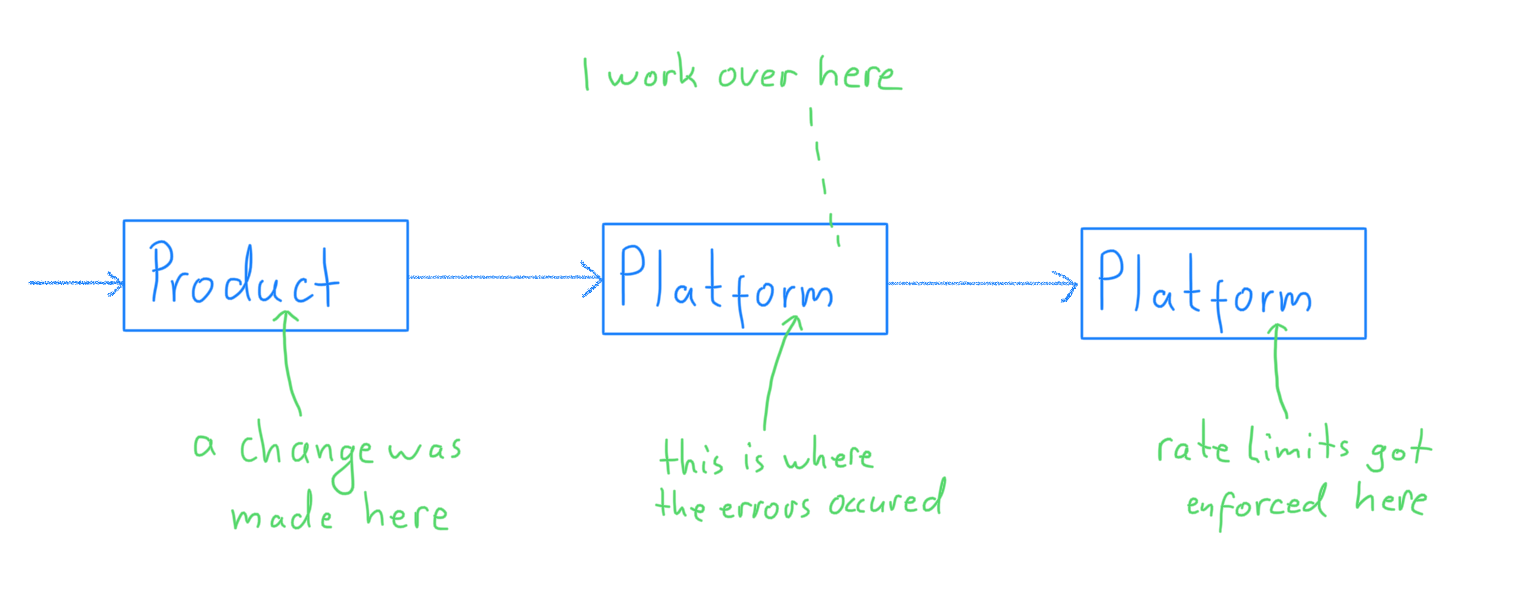
I believe things are a little clearer for you now, so lets get back to the story.
Looking for solutions
As the errors had surfaced in one of the services owned by our department, it was up to us to resolve the issue so that the product could be changed as desired.
The technical document I mentioned in the beginning listed several ideas for mitigating the errors and there was already an active discussion about which approach to pick.
I was trying to form my own opinion about what might be the best solution, but I didn’t really like any of our available options. All of them would have helped, but they also came with some undesirable consequences.
Somewhat restless I kept trying to find a better way forward. That’s when I noticed something interesting. All of the proposed solutions were trying to resolve the issues right where they occured: in the platform services owned by our own department.
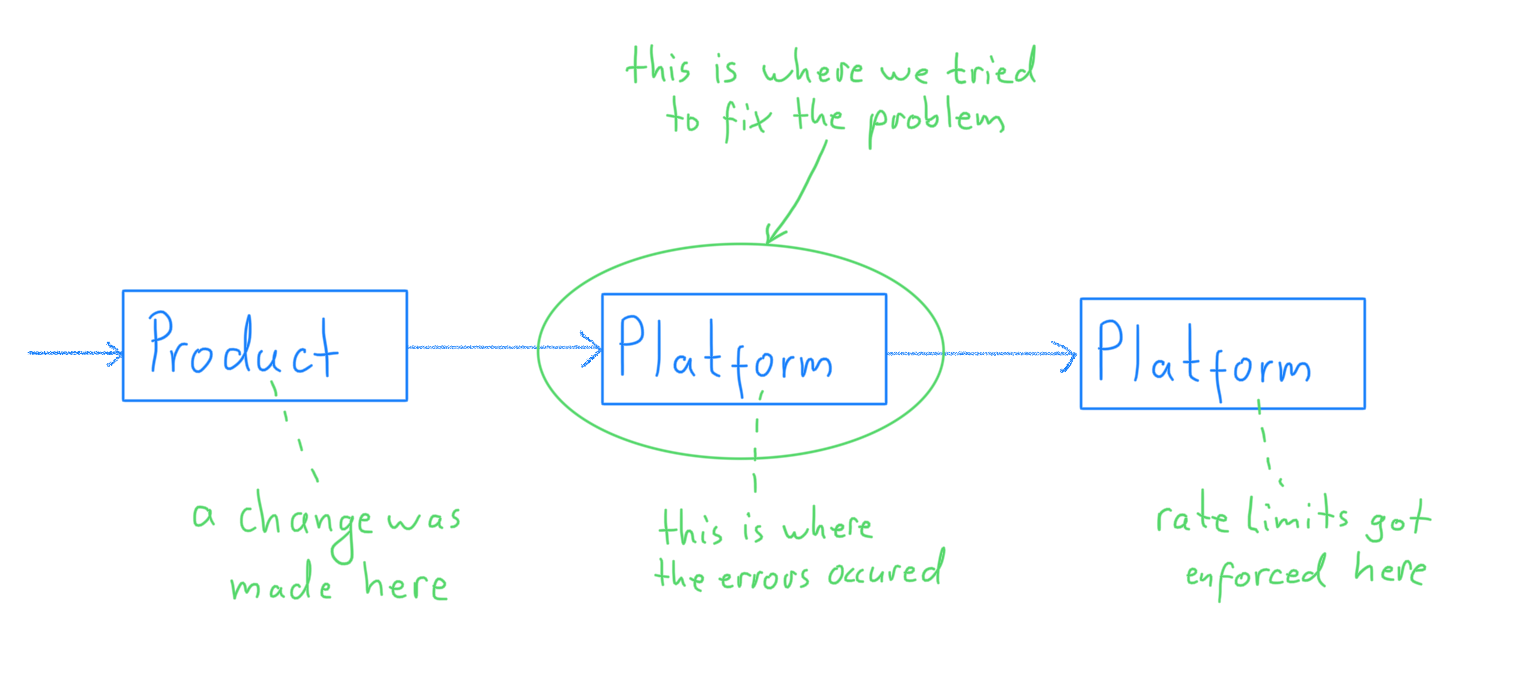
And then something else caught my attention: all the participants in the discussion were part of our own department. There was no one representing the other departments; neither from the department that depended on our systems, nor from the department that our systems depended on.
So I decided to reach out to a few of my peers in those departments to ask for help and their opinions.
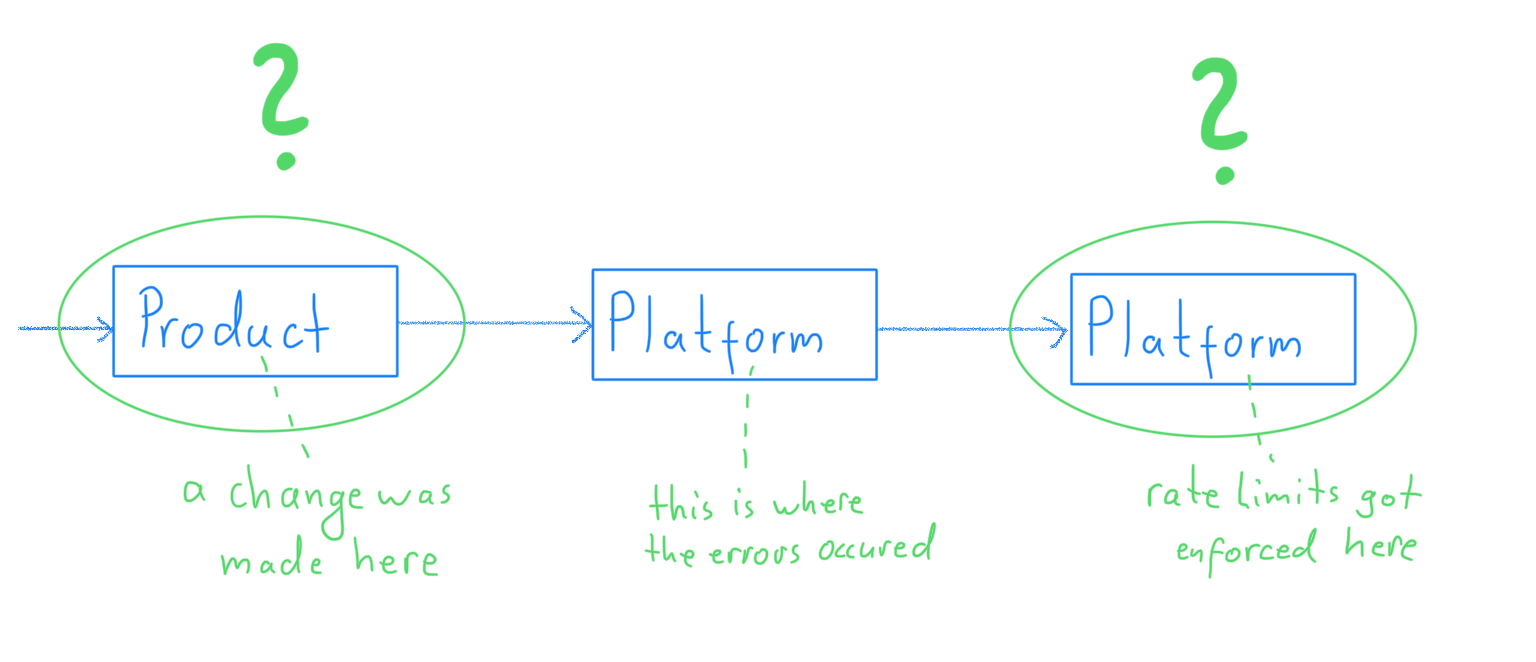
I did not anticipate what a simple solution we would find together.
The power of going across and beyond
After reaching out to a couple of developers from the other departments, it didn’t take long for someone from the product department to get back to me. A conversation pretty close to the following one unfolded:
Me: Hey, we are experiencing some issues with the additional load caused by the most recent changes. We’re looking for a way to reduce traffic and I was wondering if you could help me understand a thing or two?
Developer: Yeah, I’ve heard about those problems, but I thought your team was taking care of it already?
Me: We are, but so far none of the solutions we came up with feels particularly great. So I was wondering if there was a better way. Can you think of one?
Developer: Hm, now that you ask … I think there is something we could do. The majority of the traffic we generate is really not necessary. We are running a lot of queries even though we know the answer to them already. We can definitely get rid of that traffic. It’s just that we didn’t think these queries could cause problems when we wrote them.
And indeed. It turned out that most of the headache-causing traffic was simply not necessary and could easily be avoided. A couple of code changes and one deployment later, we did see a significant drop in traffic and with that all of the rate limiting errors vanished.
Problem solved.
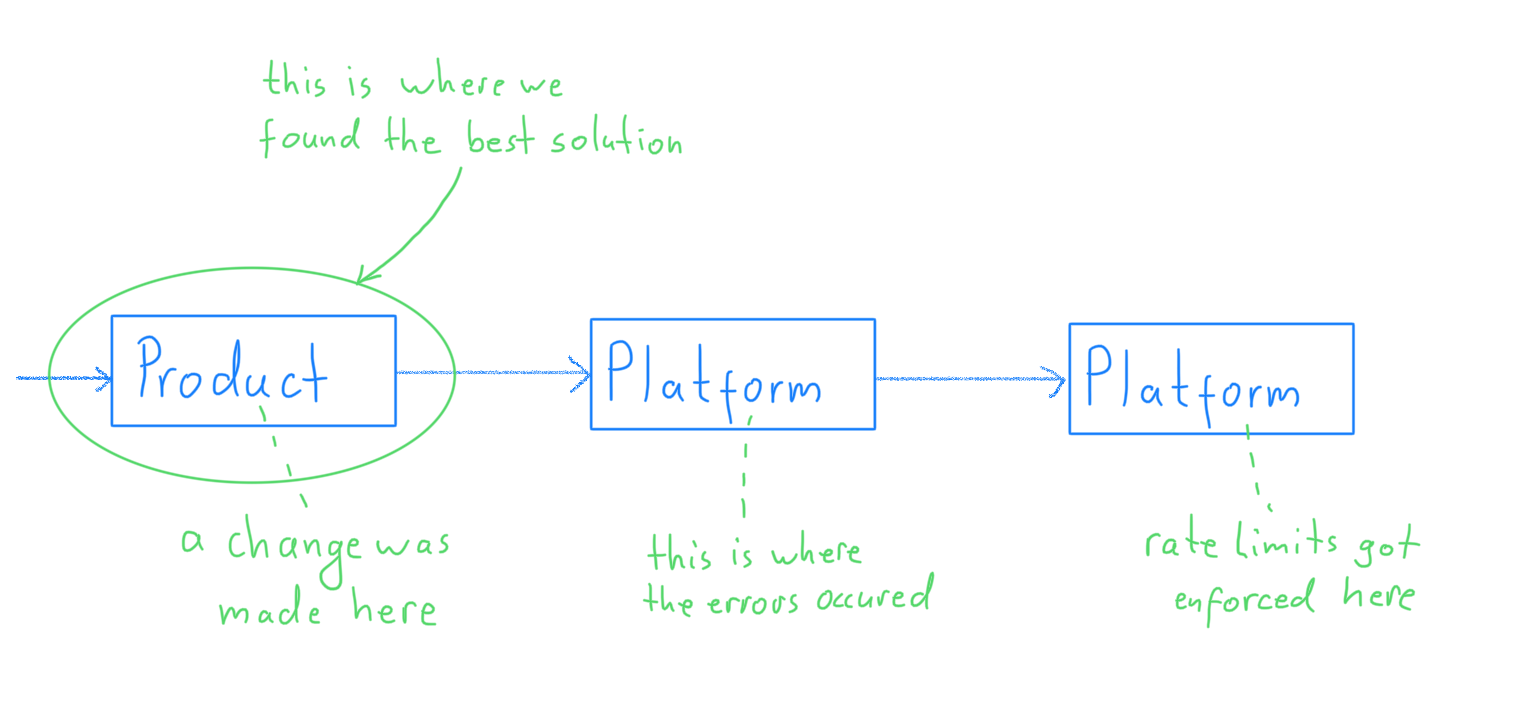
All it took was for one developer from the product department to set their mind to the problem. Once that had happened, a most elegant solution was found.
Look at the whole system, not just the parts
So, is there anything we can learn from this story? I think so!
Every time you discover a problem in the software that you and your colleagues are working on, remind yourself that that software is just a part of a larger system.
And while it is tempting to focus your problem solving only on the part of the system you know most about, you should always remember this: What matters is how well the entire system works and not just how well each part of it works.
Taking a step back to look at the larger picture every now and then will yield some mighty rewards.